您當(dāng)前的位置:檢測資訊 > 科研開發(fā)
嘉峪檢測網(wǎng) 2025-04-16 15:48
片上系統(tǒng)(SoC)的創(chuàng)建者通常希望從他們的系統(tǒng)中榨取最大的性能,這是很自然的事情。為了達到這一目的,使用高性能的知識產(chǎn)權(quán)(IP)內(nèi)核,包括中央處理器(CPU)內(nèi)核,是一個常見的策略。但是,使用最新的高端CPU內(nèi)核會帶來較高的成本,這可能比中檔內(nèi)核高出5到10倍。
SoC架構(gòu)師在設(shè)計時需要根據(jù)目標(biāo)市場和應(yīng)用做出多種權(quán)衡考慮。雖然有些設(shè)計不惜一切代價追求性能,但更多的嵌入式系統(tǒng)項目則更傾向于在盡可能低的成本下實現(xiàn)最佳性能。
對于那些使用低成本、低性能處理器內(nèi)核的設(shè)計團隊來說,提高效率變得尤為重要。通常,他們可能不知道有一種相對簡單的方案能夠為其SoC的CPU性能提升多達32%。
1.性能、性能、性能
SoC中常用的大多數(shù)CPU內(nèi)核基本上都是基于精簡指令集計算機(RISC)架構(gòu)的,比如RISC-V聯(lián)盟成員開發(fā)的RISC-V處理器內(nèi)核,以及Arm公司的Cortex-A(應(yīng)用處理器)、Cortex-R(實時處理器)和Cortex-M(微控制器處理器)等內(nèi)核。
經(jīng)典的標(biāo)量RISC處理器旨在每個時鐘周期獲取并執(zhí)行一條指令。實現(xiàn)這一目標(biāo)的第一步是采用經(jīng)典的RISC處理器流水線,其中包括五種狀態(tài):指令獲取(IF)、指令解碼(ID)、執(zhí)行(EX)、內(nèi)存訪問(MA)和寫回(WB)。如圖1所示。
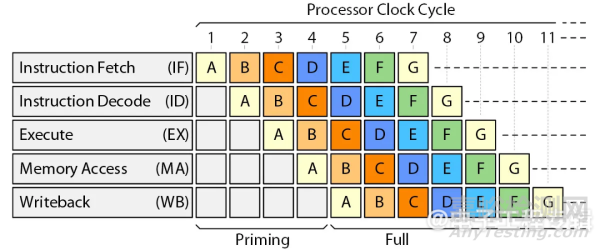
圖1:經(jīng)典RISC流水線。(來源:Arteris)
當(dāng)應(yīng)用程序開始運行時,需要幾個周期來加載流水線。一旦流水線裝滿,處理器就可以實現(xiàn)其最大性能目標(biāo),即每個時鐘周期執(zhí)行一條指令,盡管在實踐中這種情況并不多見。
2.中檔處理器的兩種常見場景
CPU性能取決于兩個因素:計算能力和數(shù)據(jù)的可用性。如果處理器在需要指令和數(shù)據(jù)時無法獲取它們,就會導(dǎo)致流水線中的氣泡。
考慮兩種常見的中檔處理器配置:單處理器內(nèi)核(圖2a)和處理器集群(圖2b)。假設(shè)單個處理器只有一個一級(L1)緩存,而集群中的每個內(nèi)核(通常是2、4或8個內(nèi)核)都有自己專用的L1緩存,這些內(nèi)核共享一個公共的二級(L2)緩存。
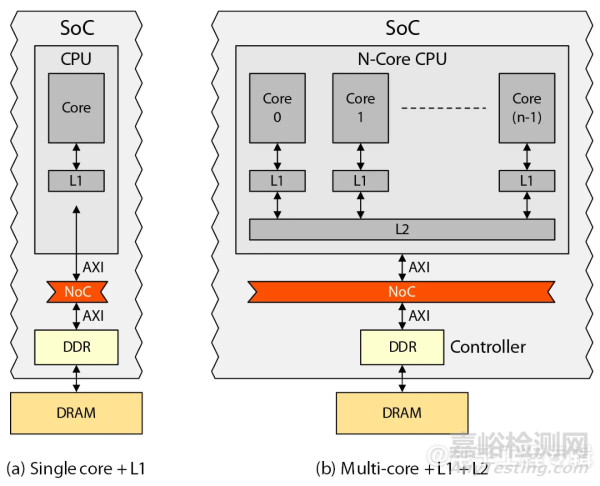
圖2:兩種常見的中檔處理器配置。(來源:Arteris)
在這些場景中,所有的IP(包括處理器和加速器)都通過片上網(wǎng)絡(luò)(NoC)連接。此外,DDR控制器IP用于與外部DRAM內(nèi)存通信。訪問外部DRAM可能需要100到200個處理器時鐘周期,我們假設(shè)在這個討論中為150個時鐘周期。
現(xiàn)在,假設(shè)運行1,000,000條指令,我們來看看圖2a中所示的單核場景。我們來簡單做個思維實驗,看看如果沒有L1緩存會發(fā)生什么。在這種情況下,CPU每次需要訪問主內(nèi)存來獲取每條指令和數(shù)據(jù)。因為每次內(nèi)存訪問需要150個處理器時鐘周期,所以順序執(zhí)行的CPU效率非常低,僅為1,000,000條指令/(1,000,000×150)個時鐘周期=1/150或0.67%。
這也就是CPU配備緩存的原因。我們再來做第二個思維實驗,假設(shè)L1緩存與CPU同頻運行,并且訪問L1緩存只需一個時鐘周期。如果L1緩存無限大,能夠?qū)RAM中的所有內(nèi)容復(fù)制進去,那么1,000,000條指令就能在1,000,000個時鐘周期內(nèi)完成執(zhí)行,從而使CPU效率達到100%。因此,CPU的理想效率就從沒有緩存時的0.67%擴展到了緩存無限大時的100%。
3.實際緩存計算和CPU效率
實際上,緩存的大小是有限的。在我們的中檔處理器示例中,典型的緩存值為16KB到64KB L1緩存,或32kB L1緩存和512KB L2緩存。在這兩種情況下,只有一小部分應(yīng)用程序及其數(shù)據(jù)可以從DRAM復(fù)制到緩存中。
即便如此,即使很小的緩存也非常有效,有兩個原因。首先,當(dāng)程序訪問某個位置的指令或數(shù)據(jù)時,它通常也需要訪問附近的位置。其次,程序通常包含多個嵌套循環(huán),在程序執(zhí)行下一個任務(wù)之前,會對同一數(shù)據(jù)執(zhí)行多次操作。
因此,當(dāng)CPU請求數(shù)據(jù)時,通常可以在緩存中找到。這時稱為“緩存命中”,指令只需要一個處理器時鐘周期。如果數(shù)據(jù)不在緩存中,則稱為“緩存未命中”。此時,訪問DRAM需要150個處理器時鐘周期。
在我們的單處理器場景中(圖2a),假設(shè)典型的緩存命中率為95%,那么1,000,000條指令中的950,000條指令只需要一個處理器時鐘周期。剩余的50,000條指令每條需要150個時鐘周期。這樣,L1專用的CPU效率可以計算為1,000,000/((950,000×1)+(50,000×150))≈12%。
假設(shè)我們增加一個L2緩存。L2緩存通常以處理器時鐘頻率的一半運行,每次訪問需要20個處理器時鐘周期。假設(shè)L2緩存同樣有95%的命中率,那么它就能以此速率解決50,000次L1緩存未命中的47,500次。剩下的2,500次未命中則需要訪問主內(nèi)存。這樣,基于L1+L2的CPU效率可以計算為1,000,000/((950,000×1)+(47,500×20)+(2,500×150))≈44%。
為了便于討論,我們再假設(shè)增加一個緩存層級。這時,新的緩存通常以與L2相同的時鐘頻率運行,每次訪問需要40個時鐘周期。假設(shè)這個新層級也有95%的命中率,則CPU效率將為1,000,000/((950,000×1)+(47,500×20)+(2,375×40)+(125×150))≈50%。
4.CodaCache作為性能增強方案
如圖3所示,添加額外的緩存層級來服務(wù)CPU或CPU集群是Arteris的CodaCache IP的一種可能部署方式。在上述示例中,這種部署稱為專用緩存(DC),因為它專門服務(wù)于一個IP——CPU或CPU集群。

圖3:使用CodaCache為CPU提供額外的緩存層級。(來源:Arteris)
每個CodaCache實例的大小可以是64KB到8MB。例如,當(dāng)與只有L1緩存的CPU結(jié)合使用時(圖3a),CodaCache可以將性能從12%提高到44%,效率提升了32%,性能提升了267%。
值得注意的是,這只是CodaCache的一種可能部署方式。其他CodaCache IP也可以分配為其他IP的專用緩存,以加速它們的性能。此外,CodaCache還可以部署在NoC和DDR控制器之間,作為最后一級緩存(LLC),以加速整個SoC。
5.總結(jié)
CodaCache是一種可配置的獨立非相干緩存IP,通過其先進的架構(gòu)提供了獨特的商業(yè)價值,提高了系統(tǒng)性能、數(shù)據(jù)局部性、可擴展性、能效、應(yīng)用程序響應(yīng)能力、成本優(yōu)化和市場競爭力。
就像一氧化二氮可用于提升一級方程式賽車的性能一樣,CodaCache可用于顯著提升SoC和SoC CPU的性能。
(原文刊登于EE Times美國版,參考原文:How to Turbo Charge Your SoC's CPU(s) ,作者為Arteris公司客戶服務(wù)副總裁,由Franklin Zhao編譯)

來源:電子工程專輯


